






























by Saurabh Sharma, on Jun 5, 2021 12:23:10 PM
Intelligent document processing (IDP) from a product architecture perspective is a composite solution where OCR plays the role of a “component” for data extraction. Some users have experimented with the combination of python code with OCR in the past to develop what was then termed as “intelligent OCR”, however, the level of accuracy achieved was still not good enough. What IDP brings to the table are pre-processing and post-processing stages along with AI/ML capabilities, which improve the accuracy of data extraction and deliver straight-through processing (STP) with relatively better accuracy.
What is OCR? A legacy tool with limitations in delivering accuracy.
Various estimates indicate that 80% of enterprise data is unstructured and it is difficult to automate processes having unstructured data with traditional automation tools used in back office automation. There is a rising need for enterprises to process large volumes of semi-structured and unstructured documents with greater accuracy and speed. Even with the best document quality and scanners, OCR in the best case scenario can deliver a maximum accuracy of 60%, which is not good enough. Users have qualms about whether it would take more time in performing manual corrections than the time that was saved by using OCR for data extraction. Moreover, OCR cannot deliver straight-through processing (STP) with accuracy. IDP as a document processing product involves pre-processing and post-processing stages, the first one primes the document in terms of shape and size and the second one ensures that a greater degree of accuracy in processing unstructured data can be achieved. Everest Group presents this in a reference architecture for IDP.
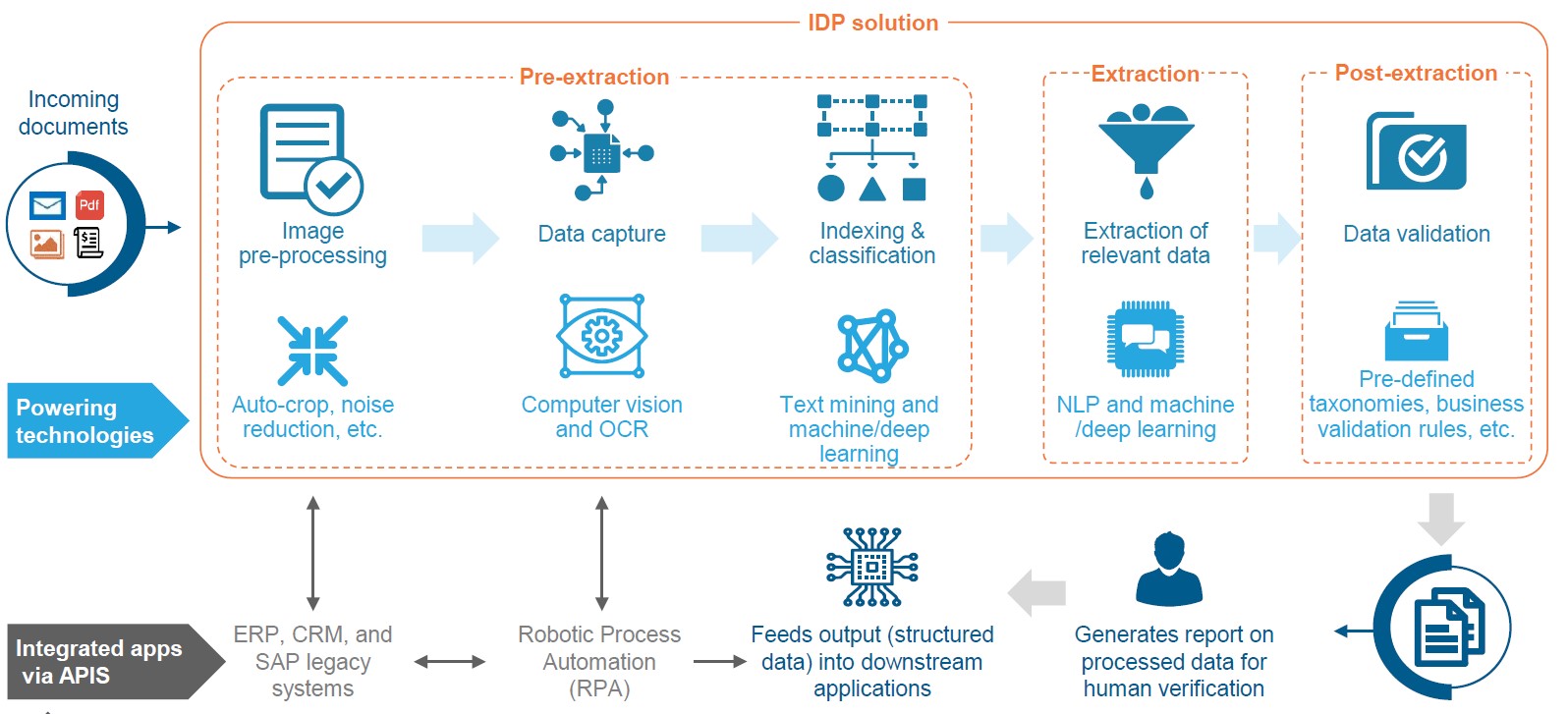
Source: Everest Group
The availability of AI/ML capabilities with an IDP tool ensures that the strike rate in terms of processing data is significantly higher than a mere OCR tool. IDP tools, in principle, are supposed to function with minimal training in terms of minor template changes, with OCR that type of flexibility does not exist. This comparison is a bit moot as IDP is a product where OCR is just a component, OCR on its own cannot compete with IDP. However, OCR tools or APIs continue to be used for data extraction in IDP products, with additional capabilities delivering smart automation of documents. Pre-built AI/ML capabilities and business rules enable automated verification & validation of data and continuous learning & improvements based on AI/ML algorithms and user inputs. IDP tools combine OCR, data capture, and AI/ML to automate the retrieval, understanding, and integration of documents required for executing a business process.
What is a template-free approach for implementing IDP solutions?
In general, the expectation with IDP tools used in back office automation is that users should need to do only minimal training for minor template changes. However, enterprises that deal with hundreds to thousands of vendors on a monthly basis realize that creating and maintaining templates for invoices is a cumbersome process. The number of consulting hours devoted to get up and running with templates for disparate document types can quickly add to overall costs. In such cases, it is easy to realize that a template-free approach to IDP can significantly reduce total cost of ownership (TCO) of IDP and enables faster time-to-automation. No need to wait for months and months just for creating templates, without even doing any real document automation.
What are the key use cases for IDP solutions?
Know Your Customer (KYC), invoice processing, insurance claims, patient onboarding, patient records, proof of delivery, and order forms are some of the key use cases for IDP solutions. IDP software is of good use in industry-specific processes, such as customer onboarding, mortgage processing, trade finance, and legal documents. Within the finance and accounting domain, accounts payable and accounts receivable are common use cases for IDP, understandably given the high volume and error-prone nature of such processes.